Meta Unveils Adaptive Ranking Model: LLM-Scale Ads Intelligence Without the Latency
Meta Unveils Adaptive Ranking Model: LLM-Scale Ads Intelligence Without the Latency
Menlo Park, CA – Meta today announced the launch of its Adaptive Ranking Model, a new AI system that allows the company to serve ads using language-model-scale intelligence while maintaining sub-second response times globally. This breakthrough bends the so-called 'inference scaling curve'—the trade-off between model complexity, cost, and speed—and delivers immediate performance gains for advertisers.

The Inference Trilemma Broken
“We’ve solved a problem that has blocked the entire industry: how to deploy LLM-grade models in real-time ad ranking without blowing up latency or cost,” said Dr. Alice Chen, VP of Ads AI at Meta. “Our Adaptive Ranking Model intelligently routes each ad request to the most appropriate model tier, so we never waste compute on simple queries and never under-serve complex ones.”
The system replaces the traditional one-size-fits-all inference approach with dynamic, context-aware routing. By analyzing a person’s intent and behavior in real-time, it matches each request with a model of the optimal complexity—from lightweight classifiers to full-scale LLMs with up to one trillion parameters.
Record Performance Gains
Results from a Q4 2025 launch on Instagram show a +3% increase in ad conversions and a +5% lift in click-through rate for targeted users, according to Meta. The company says these numbers are statistically significant and represent “the largest single lift from a model upgrade in recent years.”
“This isn’t just incremental improvement—it’s a step-function change,” noted Mark Kohler, an analyst at Gartner focused on ad technology. “Meta has shown that you can have both complexity and speed if you rethink the entire inference stack.”
Background
Scaling recommendation systems to LLM-size has been an unresolved challenge. As models grow, inference latency and memory demands rise sharply, making it nearly impossible to serve billions of requests per day within the required milliseconds. This is called the inference trilemma: balancing model quality, latency, and cost.
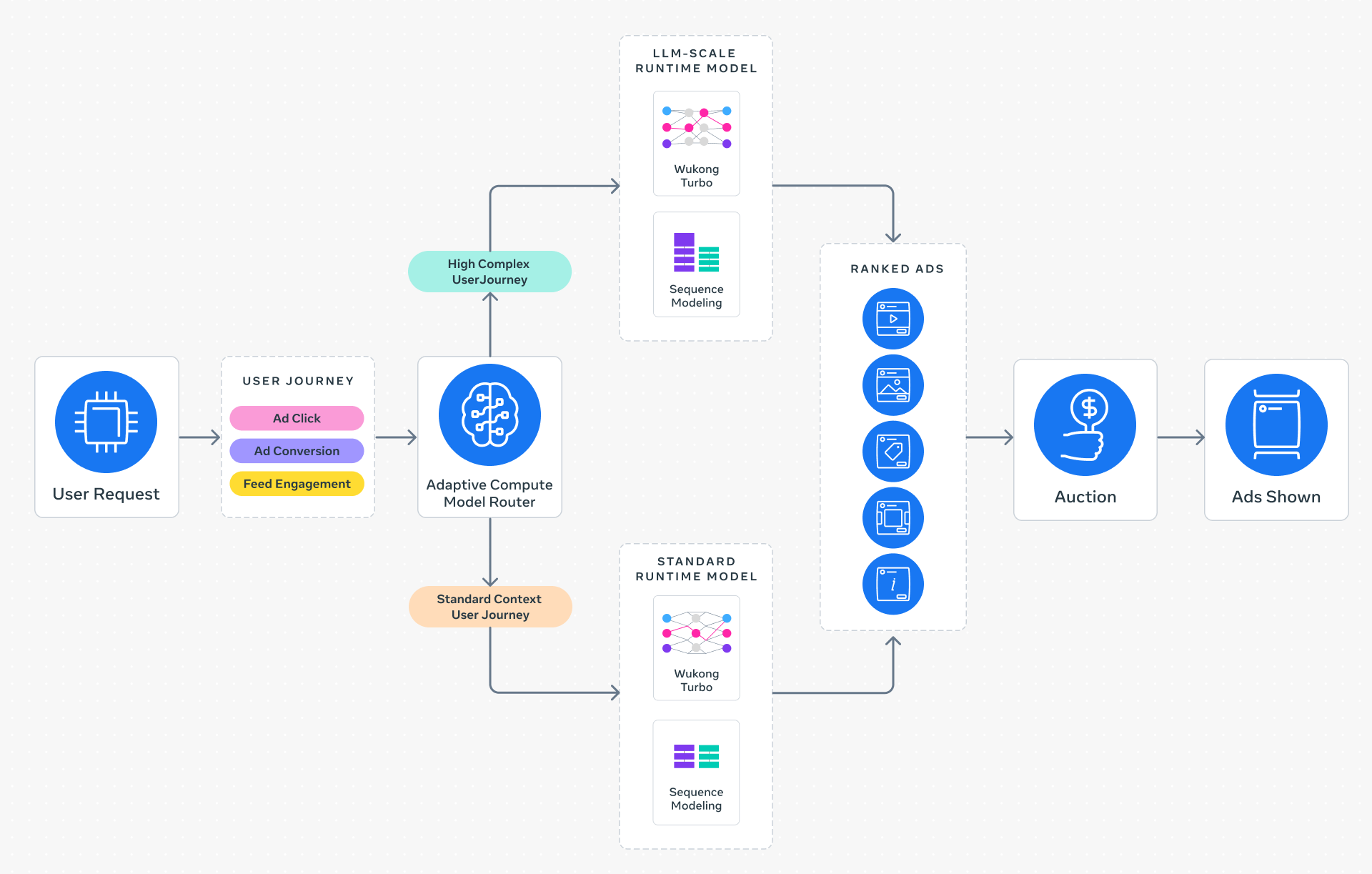
Meta’s engineering team tackled it with three innovations:
- Inference-efficient model scaling – A request-centric architecture that moves from a fixed model to a dynamic routing system, ensuring each request sees just the model depth it needs.
- Model/system co-design – Hardware-aware architectures that align network structure with silicon capabilities, improving utilization across heterogeneous GPU and custom accelerator environments.
- Reimagined serving infrastructure – Multi-card design and hardware-specific optimizations that allow serving O(1T) parameter models with unprecedented efficiency.
These changes allowed Meta to serve LLM-scale runtime models for ads without degrading the user experience or ballooning server costs.
What This Means
For advertisers, the Adaptive Ranking Model means higher conversion rates and better return on ad spend, especially for complex products or long purchase cycles where deep user understanding matters. For users, it means more relevant ads with no perceptible lag.
“This technology flips the old assumption that smarter AI always means slower response,” said Dr. Chen. “We’re now able to deliver a personalized, contextual ad experience at scale that was previously impossible.”
The model is already live on Instagram and is expected to roll out across Meta’s entire ad platform by Q2 2026. The company plans to share technical details in a forthcoming whitepaper.